Why spatial hashing?
How often have you bemoaned the lack of a simple way to cut down on the number of objects tested during collision detection or culling? Sure, one could integrate a full-blown physics library, or implement a dynamic quad-tree/kd-tree/BVH, but all of these are time consuming, and not necessarily worth it for a small game or demo. These approaches also all suffer from another drawback (which may or may not affect you, depending on the type of game): they assume the world is a fixed, finite size.
Spatial hashing, on the other hand, is lightweight, trivial to implement, and can easily deal with worlds whose dimensions vary over time.
Why another article on spatial hashing?
There are quite a number of articles on spatial hashing floating around the net, ranging all the way from lengthy academic treatises to back of the napkin sketches. Unfortunately, most of the articles towards the beginning of that spectrum aren't that friendly to the casual observer, and towards the end of the spectrum they don't tend to provide complete implementations, or neglect the more obscure (and useful) tricks.
What is a spatial hash?
A spatial hash is a 2 or 3 dimensional extension of the hash table, which should be familiar to you from the standard library or algorithms book/course of your choice. Of course, as with most such things, there is a twist...
The basic idea of a hash table is that you take a piece of data (the 'key'), run it through some function (the 'hash function') to produce a new value (the 'hash'), and then use the hash as an index into a set of slots ('buckets').
To store an object in a hash table, you run the key through the hash function, and store the object in the bucket referenced by the hash. To find an object, you run the key through the hash function, and look in the bucket referenced by the hash.
Typically the keys to a hash table would be strings, but in a spatial hash we use 2 or 3 dimensional points as the keys. And here is where the twist comes in: for a normal hash table, a good hash function distributes keys as evenly as possible across the available buckets, in an effort to keep lookup time short. The result of this is that keys which are very close (lexicographically speaking) to each other, are likely to end up in distant buckets. But in a spatial hash we are dealing with locations in space, and locality is very important to us (especially for collision detection), so our hash function will not change the distribution of the inputs.
What is this crazy pseudo-code you are using?
That is Python. If you haven't encountered Python before, or don't favour it for some reason, then it makes fairly readable pseudo-code all by itself. Even if you have a passing familiarity with Python, however, be careful of some of the container manipulation used herein.
Where do we start?
The first thing we need to do is create the spatial hash. Because I want to deal with environments of any dimension, we are going to create what I call a 'sparse' spatial hash, and this takes a single parameter: the cell/bucket size. If we were dealing with an environment of fixed and finite dimensions, we could implement a 'dense' spatial hash instead, where we divide the environment up into cells/buckets ahead of time, and pre-allocate those buckets. However, since we don't know the size of the environment, we will still divide the world into cells, but we won't pre-allocate any buckets. We will however allocate a dictionary (hash table/hash map in other languages) to store our buckets later.
def __init__(self, cell_size):
self.cell_size = cell_size
self.contents = {}
Our hash function is also very simple, and unlike a regular hash function, all it does is classify points into their surrounding cells. It takes a 2D point as its parameter, divides each element by the cell size, and casts it to an (int, int) tuple.
def _hash(self, point):
return int(point.x/self.cell_size), int(point.y/self.cell_size)
def __init__(self, cell_size):
self.cell_size = cell_size
self.contents = {}
def _hash(self, point):
return int(point.x/self.cell_size), int(point.y/self.cell_size)
How does one insert objects?
There simplest keys to insert are single points. These aren't generally that useful, but the concept is straightforward, and they might be used for way-points, or similar. The procedure is extremely simple: hash the point to find the right bucket, create the bucket if it doesn't yet exist, and insert the object into the bucket. In this implementation, each bucket is a simple Python list.
def insert_object_for_point(self, point, object):
self.contents.setdefault( self._hash(point), [] ).append( object )
Of course, we also need to insert more complex shapes. Rather than deal with the intricacies of determining which bucket(s) an arbitrary shape need to hash to, we support only one other primitive: the axis-aligned bounding-box. The axis-aligned bounding-box is cheap to compute for other primitives, provides a reasonably decent fit, and is incredibly simple to hash.
The astute among you will have already noticed a few problems with inserting objects other than simple points into the spatial hash: a) the object may overlap several cells/buckets if it is near the edge of a bucket, and b) an object may actually be larger than a single bucket. The solution to these is luckily also simple: we add the object to all relevant buckets. And the bounding-box approach comes into its own, as we can just hash the min and max points, and then iterate over the affected buckets.
def insert_object_for_box(self, box, object):
# hash the minimum and maximum points
min, max = self._hash(box.min), self._hash(box.max)
# iterate over the rectangular region
for i in range(min[0], max[0]+1):
for j in range(min[1], max[1]+1):
# append to each intersecting cell
self.contents.setdefault( (i, j), [] ).append( object )
def insert_object_for_point(self, point, object):
self.contents.setdefault( self._hash(point), [] ).append( object )
def insert_object_for_box(self, box, object):
# hash the minimum and maximum points
min, max = self._hash(box.min), self._hash(box.max)
# iterate over the rectangular region
for i in range(min[0], max[0]+1):
for j in range(min[1], max[1]+1):
# append to each intersecting cell
self.contents.setdefault( (i, j), [] ).append( object )



Hello there,
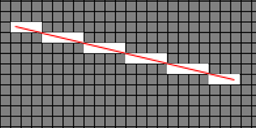
Thanks for the article :) I have my SpatialHashing implementation in place. What brought me here is that I need to create a method in my class that returns the buckets that intersect the line. In other words the rasterise algorithm. Do you know of anywhere that I can find some pseudocode or implementation for it?
Thanks!